Attache Paket: 'ggpubr'
Die folgenden Objekte sind maskiert von 'package:datawizard':
mean_sd, median_mad
library(DataExplorer)library(rbthemes)
data <-read.csv("https://raw.githubusercontent.com/sebastiansauer/statistik1/main/daten/Smartphone-Nutzung%20(Responses)%20-%20Form%20responses%201.csv")
Zunächst überprüfen wir, ob und wenn ja, in welchen Spalten es fehlende Werte gibt.
data %>%summarise((across(everything(),~sum(is.na(.x)))))
Bei den Spalten alter und preis scheint es einige fehlende Werte zu geben. Wir ersetzen diese mit dem Mittelwert der Spalten, um die anderen ausgefüllten Spalten nicht zu verlieren. Hierzu müssen wir alle numerischen Spalten in das Format double umwandenln.
data <- data %>%mutate(across(where(is.numeric), as.double))data <- data %>%mutate(across(where(is.numeric), ~replace_na(., mean(., na.rm =TRUE))))
data <- data %>%mutate(sex =factor(sex),os =factor(os))data <- data %>%mutate(sex =case_when(sex ==NA~"missing", sex =="Mann"~"männlich", sex =="Frau"~"weiblich"))data <- data %>%mutate(os =case_when(os ==NA~"missing", os =="iOS"~"iOS", os =="Android"~"Android"))
8.2 EDA
Jetzt können wir uns die Daten genauer unter die Lupe nehmen.
data %>%group_by(sex) %>%summarise(mean(price))
data %>%group_by(os) %>%summarise(mean(price))
8.2.1 Berechnung des Smartphone-Addiction-Scores
Zur Erstellung einer Spalte, die das allgemeine Maß der Smartphone-Abhängigkeit angibt, berechnen wir einfach den Mittelwert aller Items:
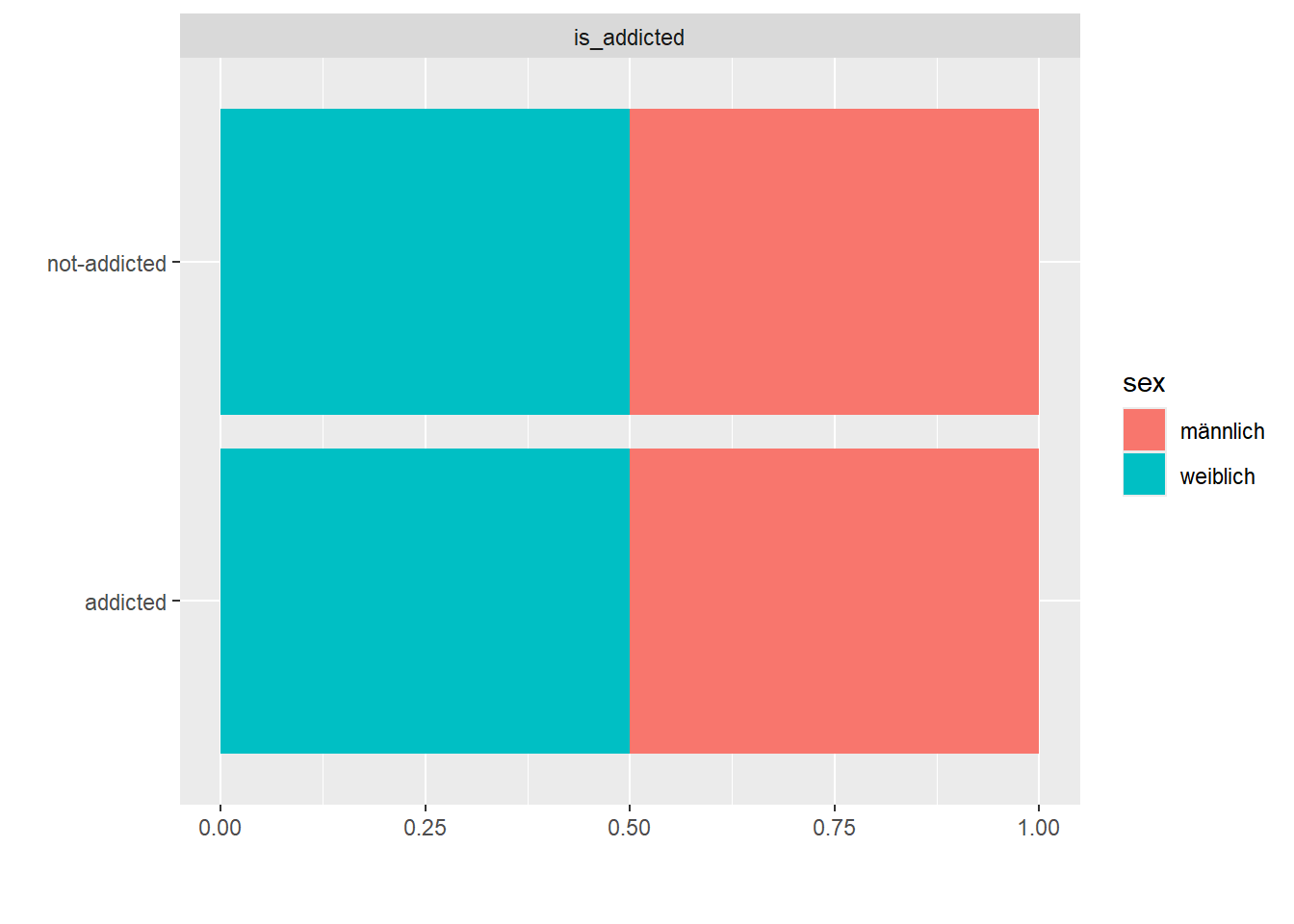
data <- data %>%mutate(addiction_score =rowMeans(across(starts_with("item")))) %>%mutate(is_addicted =case_when(addiction_score >3.1& sex =="männlich"~"addicted", addiction_score >3.3& sex =="weiblich"~"addicted",TRUE~"not-addicted"))
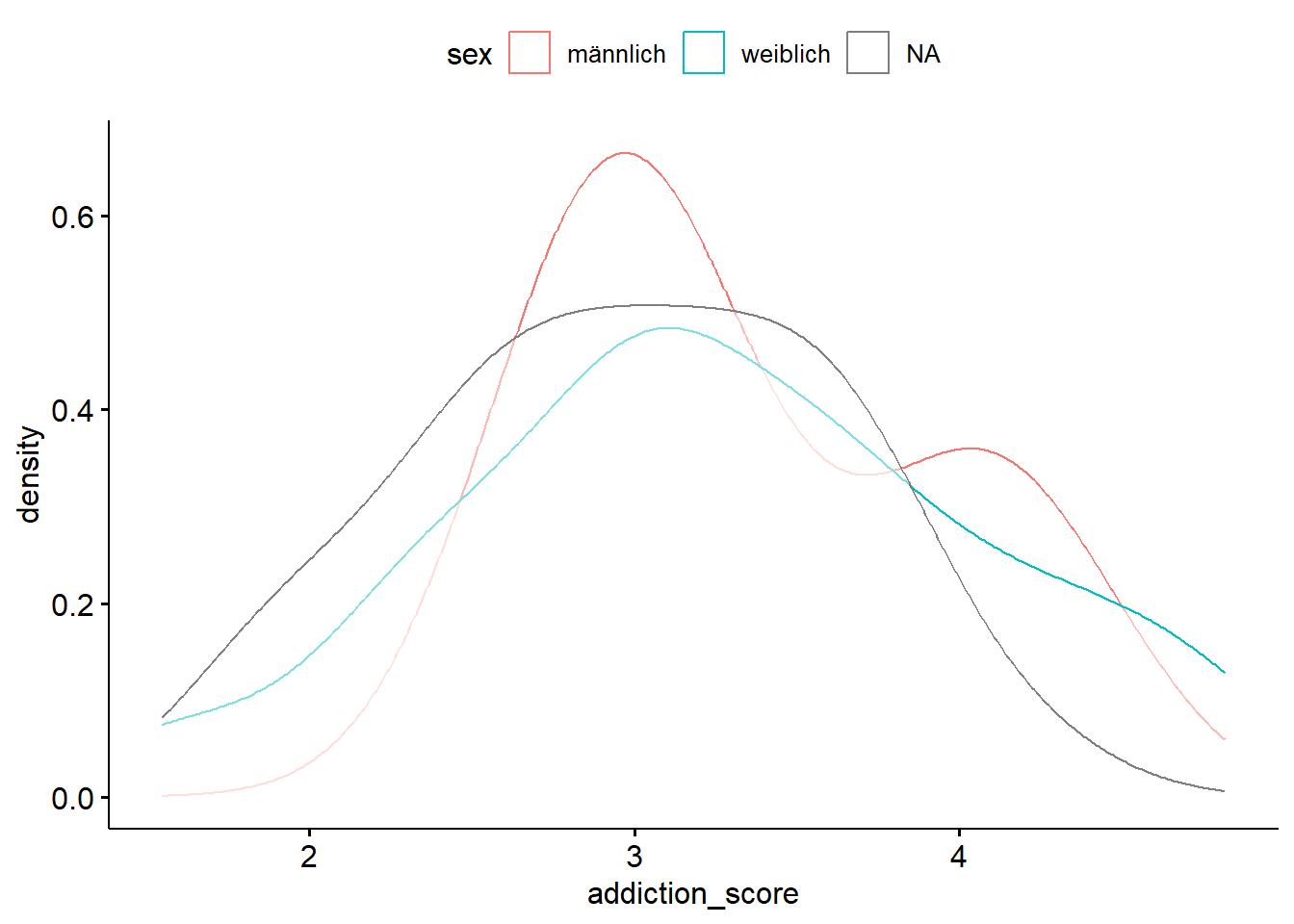
data %>%ggdensity(x ="addiction_score", color ="sex")