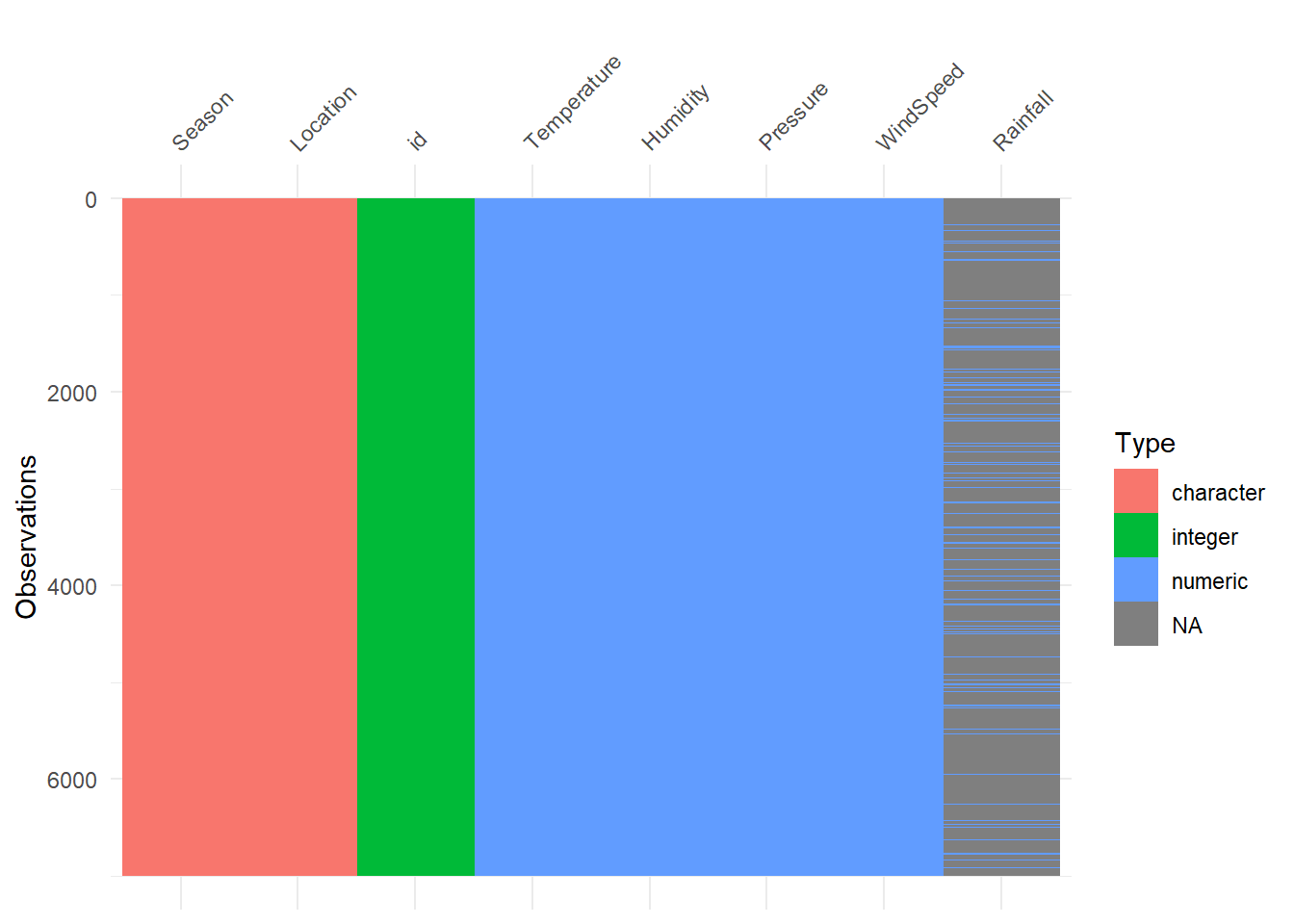
In dieser Fallstudie soll es darum gehen, was zu tun ist, wenn der Datensatz eine Spalte enthält, die fast ausschließlich aus fehlenden Werten besteht.
13.2 Datenimport
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
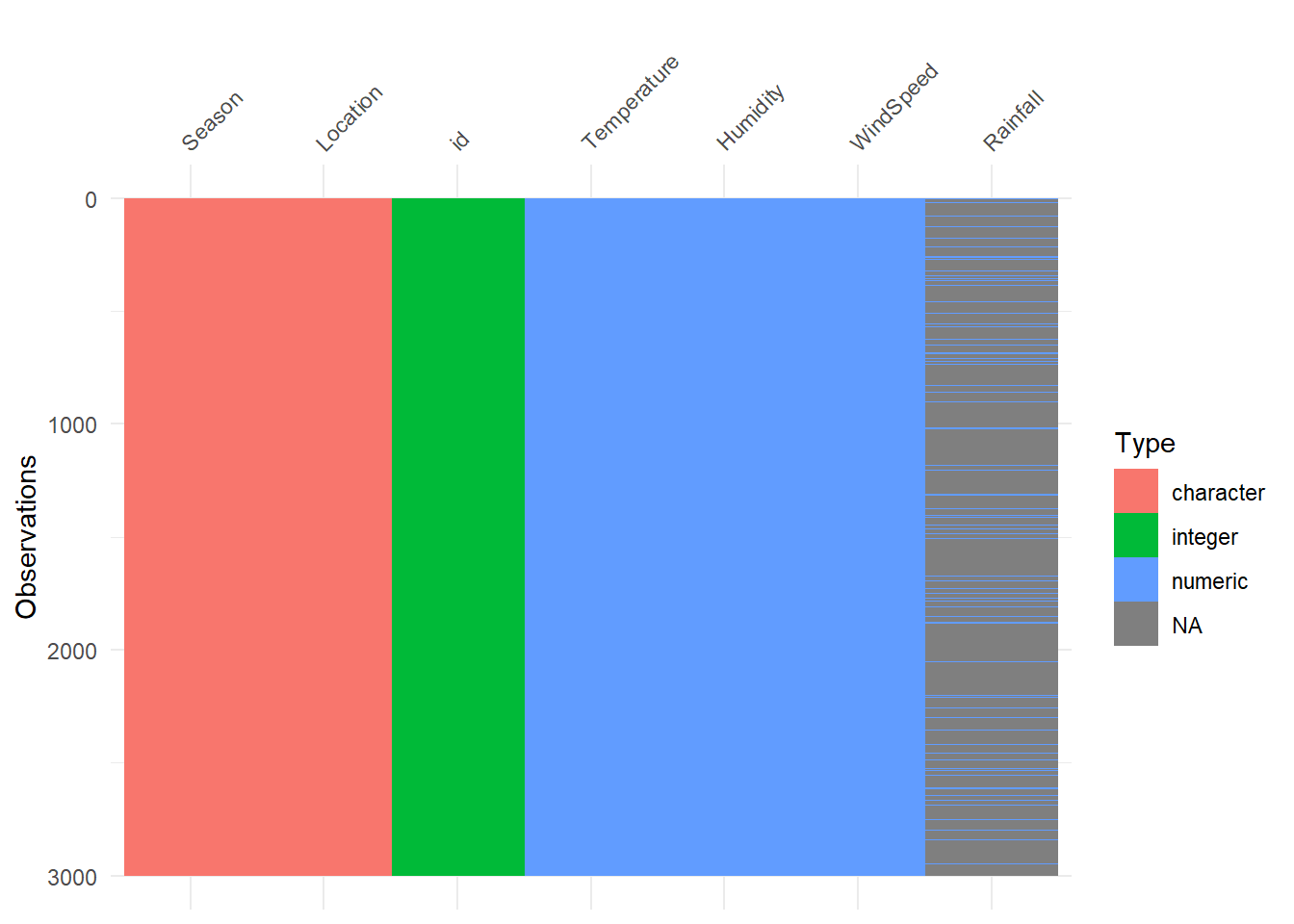
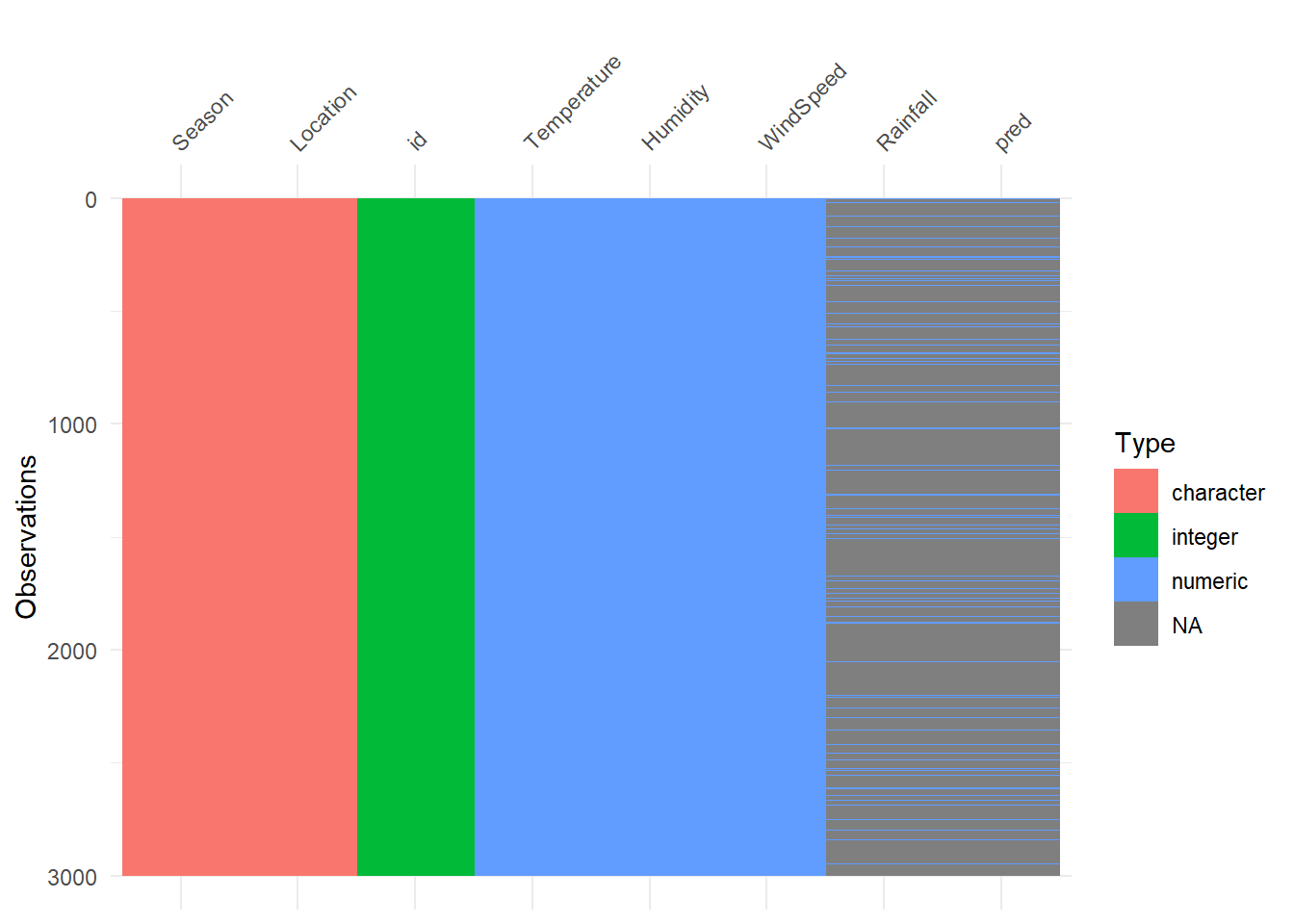
Wir erkennen auf den ersten Blick, dass die Spalte Rainfall zu 90 Prozent aus fehlenden Werten besteht. Somit enthält die Spalte kaum Informationen und sollte daher nicht verwendet oder besser gleich entfernt werden, um Verzerrungen bei Vorhersagen und Datenverlusten vorzubeugen. Wir entfernen die Spalte ganz einfach sowohl im Train, als auch im Test-Sample, indem wir dplyr’s select verwenden. Wenn wir diese Spalte für Vorhersagen nutzen, können natürlich nur Vorhersagen für die Zeilen gemacht werden, in denen Rainfall einen Wert aufweist. Das wäre in diesem Fall fatal, da dies bei nur 10 Prozent der Zeilen der Fall ist und unsere Vorhersage dann zu 90% aus NA’s bestehen würde. So würde es aussehen, wenn wir Vorhersagen mit der Spalte Rainfall machen würden:
13.4 Modellierung
lm <-lm(Pressure ~ ., data = d_train) #Der Punkt ist eine Kurzschreibweise für alle verfügbaren Variablen
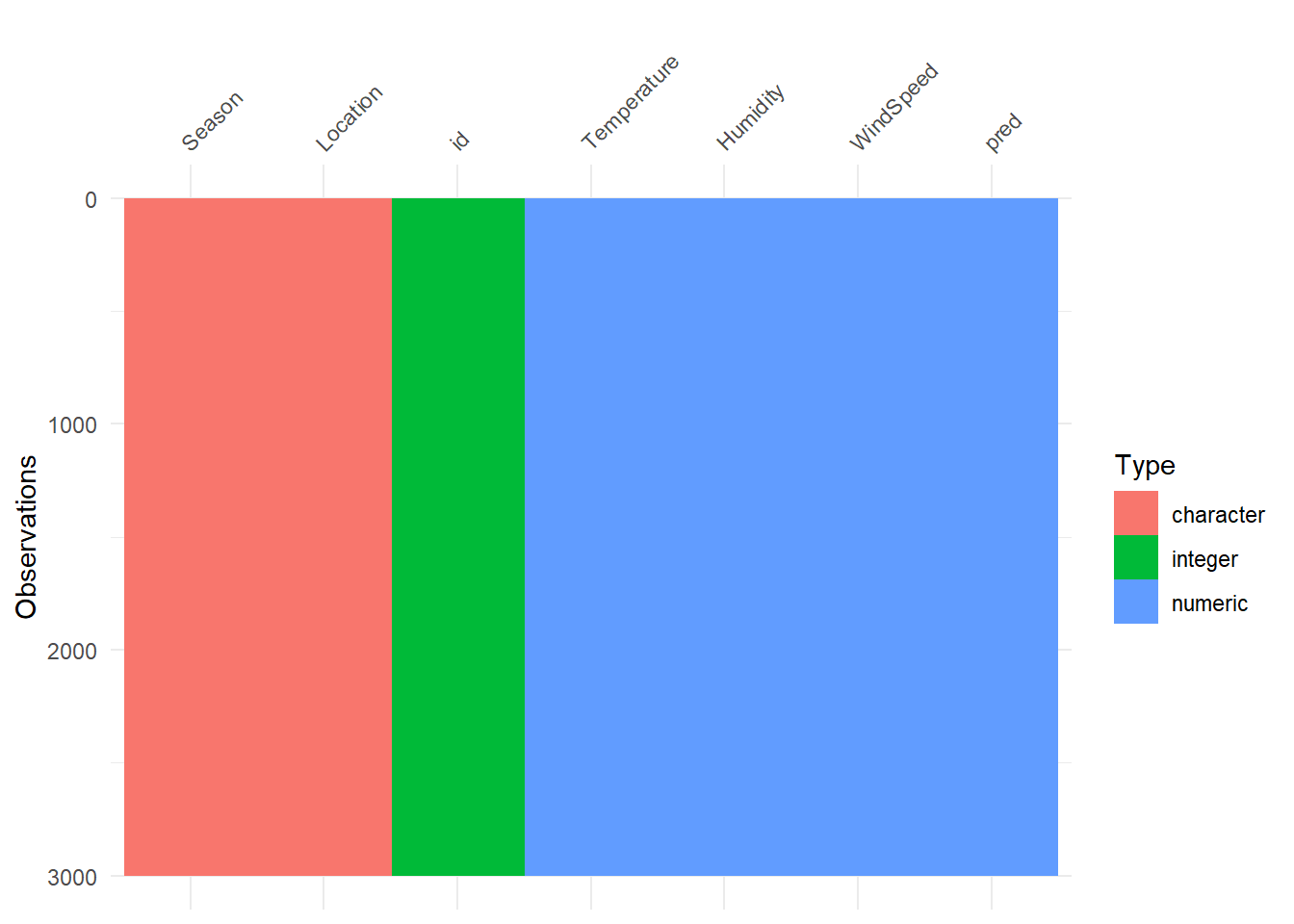
Wie wir sehen, besteht pred fast ausschließlich aus NA’s. Mit dieser Abgabe würden wir durchfallen. Also entfernen wir die Spalte einfach in beiden Datensätzen: